
What if your AI could remember past conversations, anticipate your next word, or predict the stock market’s next move? That’s the power of Recurrent Neural Networks. Unlike traditional neural networks that treat each input independently, RNNs maintain a memory of what came before, allowing them to understand sequences, context, and time-based patterns. This capability makes them the backbone of many technologies we use daily—from predictive text and voice assistants to financial forecasting and healthcare analytics.
What Is a Recurrent Neural Network (RNN)?
Image by Daniel Voigt Godoy – wikipedia
An RNN is a type of neural network designed to recognize patterns over time by remembering past information and using it to influence future predictions. 🧠 Think of RNNs as storytellers—they don’t just read the current sentence; they remember the ones before it to make sense of what comes next.
Unlike traditional neural networks where information flows in one direction only (from input to output), RNNs create loops that allow information to persist. This unique capability enables RNNs to retain information over time, which is crucial for understanding context in sequential data. This architecture gives them a form of memory, enabling them to process sequences of data where the order matters—like words in a sentence, notes in a melody, or stock prices over time. By leveraging this memory, RNNs can make predictions that are informed not just by the current input but also by previous inputs, which is essential for tasks such as language modeling, speech recognition, and time series forecasting. The ability to remember and utilize past information makes RNNs particularly powerful for applications where context is key, allowing them to capture intricate patterns that traditional networks might overlook.
The true power of RNNs lies in their ability to maintain context. Just as humans use previous experiences to interpret new information, RNNs use their internal state to give meaning to sequential data.
Key Features of RNNs
- Process sequential data of variable length
- Maintain internal memory state
- Share parameters across different time steps
- Handle inputs and outputs of different dimensions
- Learn temporal dependencies in data
How RNNs Work — The Core Mechanism
🔁 The fundamental concept behind RNNs is surprisingly elegant. Imagine listening to a song—your brain doesn’t just process the current note; it connects it to the melody that came before. That’s how RNNs interpret data.
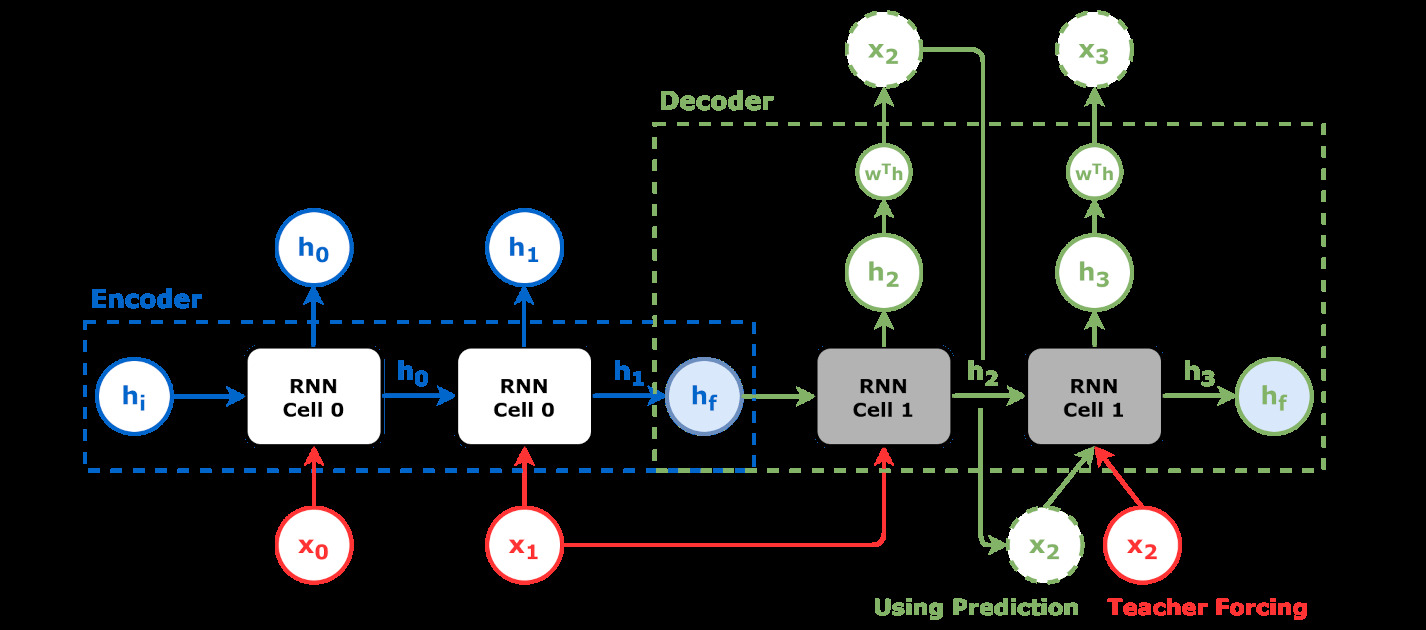
The Four Key Components
1. Sequential Input
Data enters the network one element at a time. Each element (like a word or a time step) is processed in sequence, preserving the temporal order that’s crucial for understanding context.
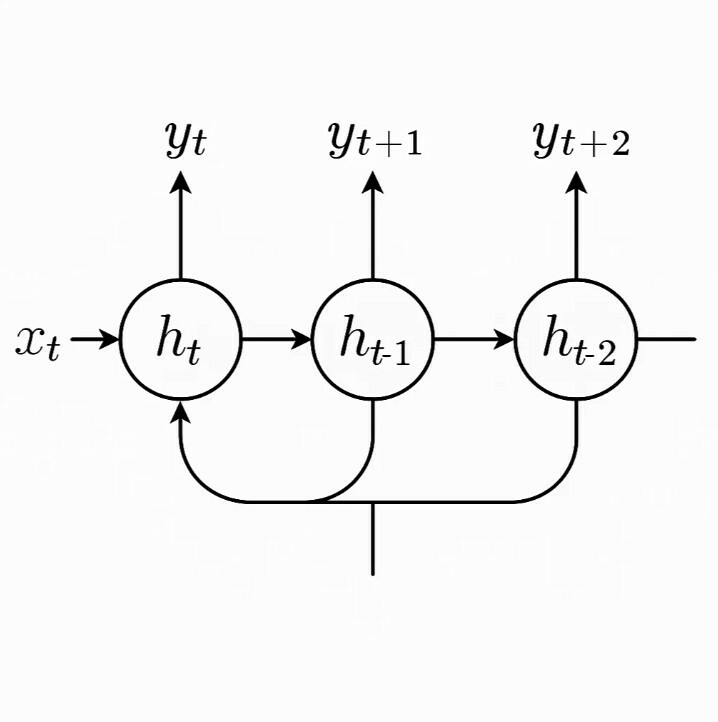
2. Hidden State
This is the network’s “memory.” At each step, the hidden state is updated based on the current input and the previous hidden state, allowing the network to maintain information about what it has seen before.
3. Feedback Loop
The output from processing one element becomes part of the input when processing the next element. This recurrent connection is what gives RNNs their power to handle sequential data.
4. Prediction
At each time step, the network makes a prediction based on both the current input and its memory of previous inputs, captured in the hidden state.
⏳ The mathematical heart of an RNN is surprisingly simple:
ht = tanh(Whhht-1 + Wxhxt + bh)
Where ht is the current hidden state, xt is the current input, and W and b are learnable parameters.
This formula shows how the current hidden state (ht) depends on both the previous hidden state (ht-1) and the current input (xt). The tanh function squashes values between -1 and 1, helping to keep the network stable during training.
Key Variants of RNNs
While the basic RNN concept is powerful, it faces challenges with long sequences. This led to the development of several important variants that address these limitations.

🧩 Vanilla RNNs
The original RNN architecture is simple but limited by what’s known as the “vanishing gradient problem.” This means that as sequences get longer, the network struggles to connect information from many steps back, effectively giving it a short-term memory.
⏳ LSTM (Long Short-Term Memory)
Developed to solve the vanishing gradient problem, LSTMs use a more complex architecture with gates that control information flow:
- Forget Gate: Decides what information to discard from the cell state
- Input Gate: Updates the cell state with new information
- Output Gate: Controls what parts of the cell state are output
This gating mechanism allows LSTMs to maintain information over long sequences, making them ideal for tasks like language modeling and speech recognition.
⚙️ GRU (Gated Recurrent Unit)
A simplified version of LSTM, GRUs combine the forget and input gates into a single “update gate” and merge the cell state and hidden state. This makes them computationally more efficient while often achieving similar performance to LSTMs.
🚀 Bidirectional RNNs
If a standard RNN reads a book page by page, a bidirectional one reads it forward and backward before deciding what the story means. By processing sequences in both directions, these networks capture context from both past and future states, improving performance on tasks like speech recognition and natural language understanding.
Which RNN Variant Should You Choose?
Selecting the right RNN architecture depends on your specific task:
- For simple sequences with immediate dependencies: Vanilla RNN
- For long sequences with important long-range dependencies: LSTM
- For faster training with comparable performance: GRU
- When future context matters as much as past context: Bidirectional RNN
Real-World Applications of RNNs
The ability to process sequential data makes RNNs incredibly versatile. Here are some of the most impactful applications:

💬 Natural Language Processing (NLP)
Text Generation
RNNs can generate coherent text by predicting the next word in a sequence, powering applications like Gmail’s Smart Compose and content generation tools.
Machine Translation
By encoding a sentence in one language and decoding it in another, RNNs form the foundation of translation systems like early versions of Google Translate.
Sentiment Analysis
RNNs excel at understanding the emotional tone of text, helping companies analyze customer feedback and social media mentions.
Chatbots
Conversational AI uses RNNs to maintain context across multiple exchanges, creating more natural interactions.
🎧 Speech Recognition
Voice assistants like Siri, Alexa, and Google Assistant use RNNs to convert sound waves into text and meaning. The sequential nature of speech makes RNNs particularly well-suited for this task.
📊 Financial Forecasting
The temporal patterns in financial data make it ideal for RNN analysis. These networks can identify trends and predict future movements in stock prices, commodity values, and economic indicators.
🏥 Healthcare
RNNs analyze patient data sequences to predict disease progression, monitor vital signs, and detect anomalies in medical readings. Their ability to process time-series data makes them valuable for personalized medicine.
📈 IoT & Time Series Analysis
In the Internet of Things ecosystem, RNNs detect anomalies in sensor data, predict equipment failures, and optimize energy consumption by recognizing patterns in usage over time.
The Transition from RNNs to Transformers
While RNNs revolutionized sequence modeling, they’ve been largely superseded by Transformer architectures in many applications. Understanding this evolution helps place RNNs in the broader context of AI development.
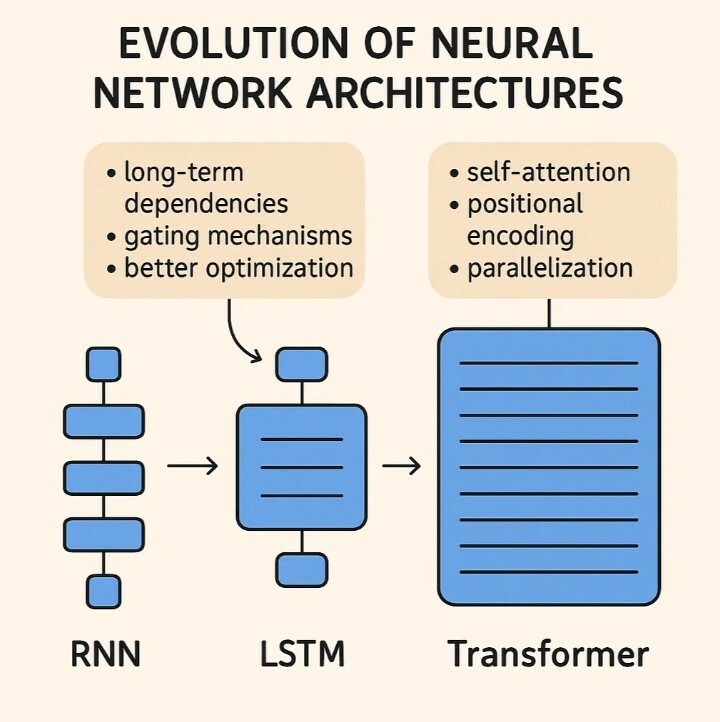
🔄 RNNs taught machines how to remember, but Transformers taught them how to focus. Instead of processing data sequentially, Transformers process everything at once using ‘attention’ mechanisms.
Limitations of RNNs
- Sequential processing limits parallelization
- Difficulty capturing very long-range dependencies
- Training can be slow and unstable
Transformer Advantages
- Parallel processing of entire sequences
- Attention mechanisms capture relationships regardless of distance
- More stable training dynamics
Despite being overtaken in many areas, RNNs remain valuable for specific applications, particularly those involving streaming data where inputs arrive one at a time, or in resource-constrained environments where the computational efficiency of smaller RNN models is beneficial.
The evolution from RNNs to Transformers wasn’t about replacement but specialization. Each architecture has its ideal use cases, and understanding both gives you a more complete AI toolkit.
Step-by-Step Guide to Learning or Applying RNNs
✅ Step 1: Understand Sequence Data
Before diving into RNNs, familiarize yourself with the properties of sequential data. Understand concepts like temporal dependencies, variable-length sequences, and the importance of order in your data.
✅ Step 2: Learn RNN Architecture Basics
Master the fundamentals of RNN architecture, including forward propagation, backpropagation through time, and the vanishing gradient problem. Frameworks like PyTorch and TensorFlow provide excellent tools for implementing these concepts.
📈 Quick Implementation Tip:
When starting with RNNs, begin with simple sequence tasks like character-level language modeling on a small dataset. This provides quick feedback and helps build intuition.
✅ Step 3: Experiment with LSTM or GRU Models
Once comfortable with basic RNNs, move on to more powerful variants like LSTM and GRU. Implement these models on small datasets and observe how they handle long-term dependencies more effectively.
✅ Step 4: Visualize Hidden States
Gain deeper insights by visualizing how the hidden states evolve over time. This helps understand what your network is “remembering” and how it’s using that information to make predictions.
✅ Step 5: Compare Performance with Newer Architectures
Benchmark your RNN models against Transformer-based approaches to understand the trade-offs in terms of accuracy, training time, and computational requirements.
Common Mistakes to Avoid

Best Practices
- Use RNNs specifically for sequential data
- Apply gradient clipping to prevent exploding gradients
- Normalize inputs for stable training
- Start with simpler models before scaling up
- Visualize hidden states to debug network behavior
Common Pitfalls
- ⚠️ Using RNNs for static data instead of sequential data
- ⚠️ Ignoring the vanishing gradient problem
- ⚠️ Not preprocessing or normalizing time-based inputs
- ⚠️ Expecting instant convergence—RNNs take longer to train
- ⚠️ Overlooking the need for sufficient sequence context
One of the most common mistakes is applying RNNs to problems where the sequential nature of data isn’t important. Before implementing an RNN, ask yourself: “Does the order of my data matter?” If not, simpler models might be more appropriate.
Remember that RNNs are specialized tools. Their power comes from their ability to handle sequences, but this same specialization makes them less efficient for non-sequential tasks.
Tools, Books & Resources
Deepen your understanding of RNNs with these carefully selected resources:

Deep Learning
Authors: Ian Goodfellow, Yoshua Bengio, Aaron Courville
Price: $72.00
The definitive textbook on deep learning with comprehensive coverage of RNNs and their variants.

Hands-On Machine Learning
Author: Aurélien Géron
Price: $59.99
Practical guide with hands-on examples of implementing RNNs using popular frameworks.

Natural Language Processing with PyTorch
Authors: Delip Rao, Brian McMahan
Price: $49.99
Focused guide on implementing RNNs for natural language processing tasks.
Understanding RNNs
- 🔁 Understand how RNNs process sequences
- 🧠 Learn the key variants (LSTM, GRU)
- ⚙️ Recognize appropriate use cases for RNNs
Implementation
- 📊 Apply to real-world time-based data
- 🚀 Compare with Transformer models
- 🔄 Keep experimenting and iterating
Conclusion
Recurrent Neural Networks gave machines the gift of memory. They taught AI to understand not just data, but time. This unique ability to remember previous inputs and use them to influence future outputs is what sets RNNs apart from traditional neural networks. And that memory still lives inside every smart system you use today—from your phone to your Netflix feed, where personalized recommendations rely heavily on understanding user behavior over time.
While newer architectures like Transformers have taken center stage in many applications, revolutionizing the way we approach tasks like language translation and image recognition, the fundamental concepts pioneered by RNNs remain crucial to understanding how machines process sequential information. RNNs were among the first to demonstrate that context matters, and their legacy continues to inform modern AI practices. By mastering RNNs, you gain not just a practical tool for specific applications, but a deeper understanding of the evolution of AI and its approach to time-based data, enabling you to appreciate the intricate dance between memory and prediction that drives intelligent behavior in machines.
The journey from simple RNNs to complex language models reflects our own human journey to understand time, memory, and prediction—core aspects of intelligence itself.
We’d love to hear how you’re using RNNs in your work or research. What challenges have you encountered? What breakthroughs have you achieved? Share your experiences and join the conversation about how these powerful neural networks are transforming your industry.

